URL Rewriting With Lambda@Edge
by Steve Marx on
I recently built paschoolstats.com, a website to help Pennsylvania parents understand the statistics and guidance the state is providing schools about COVID-19.
In the process of setting up hosting for the site, I learned a little about rewriting URLs with Lambda@Edge.
The site is a single-page app (SPA) with just one file: index.html.1 But it looks like multiple pages because I wanted pretty URLs. Specifically, I wanted the URL when people viewed the statistics for Adams County to be paschoolstats.com/adams.
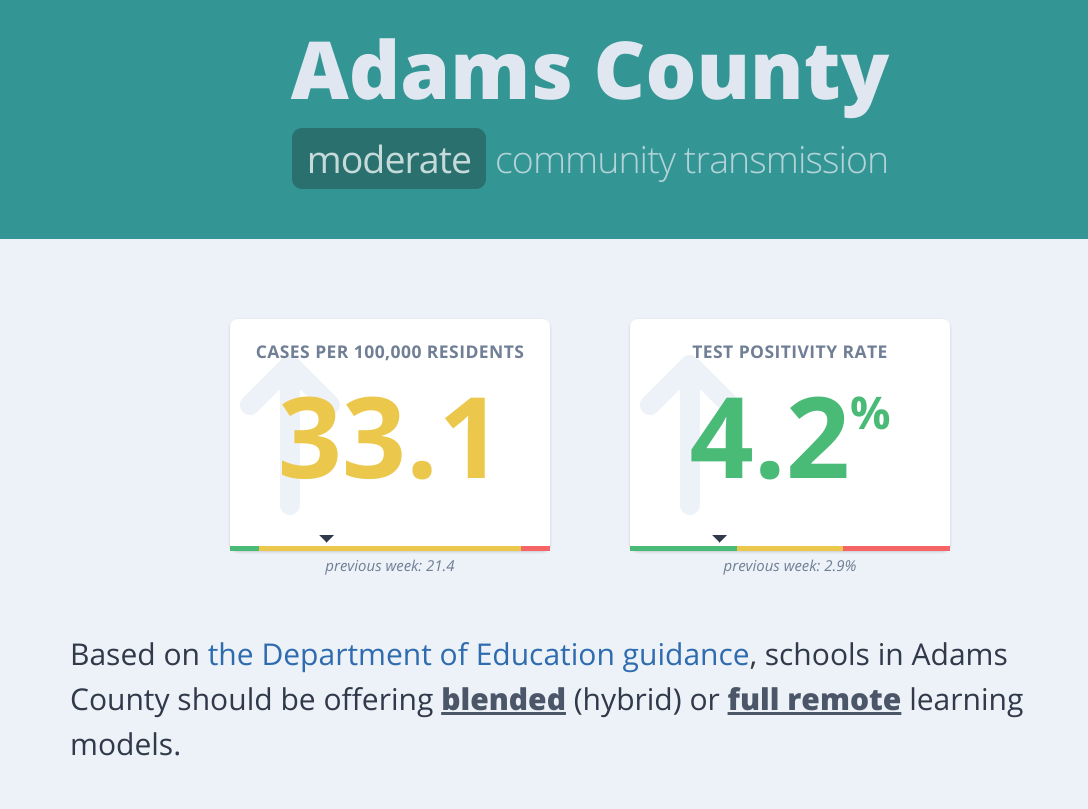
snapshot of https://paschoolstats.com/adams
This is a fairly typical requirement for SPAs, and it’s easily handled client-side with the HTML5 History API. I used SilkRouter to handle URL changes in the browser without requesting new pages from the server.
The challenge
A library like SilkRouter works great on the client, but there’s actually a server-side component too. What if the user is looking at paschoolstats.com/adams and decides to refresh the page? Or what if they bookmark that URL and visit it later directly?
Despite the URL, I just want to serve up index.html no matter what. (My client-side router will then show the right content based on the URL.) If you’re writing your own server code, this is pretty easy to do. Here’s an example in Go:
package main
import (
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
http.ServeFile(w, r, "index.html")
})
http.ListenAndServe(":8081", nil)
}
But after recently setting up my new blog on AWS using S3 and CloudFront, I was hoping to be able to stick with that platform and not have to deploy a server anywhere.
Rewriting URLs with Lambda@Edge

Lambda@Edge is a CloudFront feature that lets you run code out at “the edge”, meaning wherever CloudFront’s CDN is caching your content globally.
Within your Lambda functions, you can manipulate requests and responses. This is perfect for doing URL rewriting for a single-page app.
Here’s the Lambda function I wrote to handle the rewrite:
'use strict';
exports.handler = (evt, context, cb) => {
const { request } = evt.Records[0].cf;
const uriParts = request.uri.split("/");
// Leave URLs like /static/favicon.png alone.
if (uriParts[1] !== "static") {
request.uri = "/index.html";
}
cb(null, request);
}
Triggering the Lambda function
Functions you write with Lambda@Edge can be run in response to four different CloudFront events that happen in this order:
- Viewer request – runs for every request, before checking the cache
- Origin request – runs on a cache miss, right before fetching from the origin
- Origin response – runs after fetching from the origin but before caching
- Viewer response – runs right before delivering the content
Two of these events stand out as being relevant: viewer request and origin request. In both cases, you have a request URL that you can rewrite, but the performance characteristics of the two are different.
Viewer request
The viewer request event happens right away, before CloudFront even checks its cache. If you rewrite a URL here, things happen like this:
- A request comes in for
/adams. - The Lambda function rewrites the URL to
/index.html. - CloudFront checks the cache. On a cache hit, the file is returned.
- On a cache miss, CloudFront fetches the file from S3, caches it for subsequent requests, and returns it to the viewer.
This is great because once someone’s loaded the home page, every other page will already be cached.
The downside of this approach is that your Lambda function has to be invoked on every request no matter what.
Origin request
The origin request event happens right before a file is fetched from the origin. If you rewrite a URL here, things happen like this:
- A request comes in for
/adams. - CloudFront checks the cache. On a cache hit, the file is returned.
- On a cache miss, the Lambda function rewrites the URL to
/index.htmland CloudFront fetches that file from S3, caches it for subsequent requests, and returns it to the viewer.
This is great because cache hits are nice and fast, without having to execute the Lambda function at all.
The downside of this approach is that there are more cache misses. /adams has to be cached separately from /allegheny, etc.
Which is better?
As I researched the options in the usual places (mostly StackOverflow), I found that recommendations varied. I was unable to find any discussion of the tradeoffs involved.
I chose the origin request event simply because it was the first solution I saw. Performance wasn’t a big concern for me, but this is probably the faster option for an app like mine where the number of possible URLs is small. They’ll all get cached fairly quickly, and then my Lambda function never has to run again.
-
Okay, there’s also a favicon.png. You got me. ↩︎